- Word2Vec의 배경
Word2Vec는 원래 인공 신경망 연구에서 태어났으며 같은 맥락을 지닌 단어는 가까운 의미를 지니고 있다는 전제에서 출발한다. Word2Vec는 텍스트 문서를 통해 학습을 진행하며, 어떤 단어에 근처(전후 5-10단어 정도)에서 등장하는 다른 단어들의 출현 빈도를 이용한다. 이는 유사한 의미의 단어들은 문장의 가까운 위치에서 함꼐 출현할 가능성이 높기 때문에, 학습을 반복해 나가는 과정에서 같이 나오는 단어들이 가까운 좌표(벡터)를 갖도록 학습해나간다.
Word2Vec 개발에 주도적인 역할을 담당한 Mikolov는 14년 8월 구글을 퇴사하고 페이스북으로 이적한 것으로 보이며, 벡터 해석을 단어에서 구문까지 확장시킨 Paragraph2Vec의 구현에 주력하고 있다고 한다. Paragraph2Vec에 대한 논문은 현재 스텐포드 대학을 통해 공개되어 있으며 아래 URL에서 열람이 가능하다.
출처 : http://www.moreagile.net/2014/11/word2vec.html
Word2Vec은 단순히 단어들이 앞뒤로 서로 같이 나오는지 아닌지의 정보를 이용해 학습한다. 따라서 아주 추상적인 동사나 형용사는 명사에 비해서 제대로 된 학습이 어려울 수 있다. (추상적인 단어일수록 훨씬 더 긴 문장간의 관계를 볼 수 있는 recurrent weight가 필요하다고 추측해본다.) 다만 그럼에도 불구하고 수 없이 많은 데이터를 보면 동사들이 어떤 목적어를 취하는 지 그 규칙성을 파악함으로써, 어느정도는 동사들간의 의미관계도 학습이 가능하다고 본다.
예를 들어 eat 와 ate는 서로 비슷한 목적어들을 취할 것이므로 비슷한 의미를 지닌 다는 것을 학습할 수 있을 것이다. 동시에 신기한 점은 학습이 충분히 이루어진 벡터스페이스 상에서는 eat과 ate 두점에 대한 벡터의 거리가, take와 took의 벡터의 차이와 같아질 수 있다는 점이다. 즉 "과거를 의미하는 벡터"를 학습한 것이다. 이를 통해 단어간의 덧셈, 뺄셈을 시연한 신기한 데모는 아래에서 소개되는 구글 유튜브 동영상을 보기바란다.
Word2Vec의 모델은 딥뉴럴 네트워크가 아니지만, Word2Vec의 구조는 대략 2층짜리(input, output만 있는) 뉴럴 네트워크라고 볼 수 있다. 즉 섈로우한 모델이라고 볼 수 있다. 이는 근래의 뉴럴넷의 성공으로부터 나온 구조로 hidden layer를 없애고, 연산량 최적화를 위해 굉장히 많은 노력을 들인 모델이다. (Efficient estimation of word representations in vector space 논문을 보면 논문의 상당 부분이 연산량 최적화에 초점이 맞춰져있다.)
그래서 일반적인 RNN같은 뉴럴네트워크와 달리, 학습속도가 엄청나게 빨라서 매우 큰 데이터(기가바이트 단위)도 손쉽게 학습시킬 수 있다는게 큰 장점이다. RNN같은 매우 Deep한 뉴럴네트워크를 이용할 경우, 저렇게 엄청난 량의 데이터를 학습하는 것은 시간상 불가능에 가깝다. 그래서 RNN으로 적은량의 데이터를 오래 학습하는 것보단, 모델은 얕지만 무조건 많은량의 데이터를 보는 것이 word의 representation을 찾는 데 있어서는 더 좋은 성능을 보이는 것 같다. 그래서 Word2Vec은 현재 language를 다루는 많은 연구들에서 단어를 전처리하는 기본 공식처럼 사용되고 있다.
- Word2Vec의 구조
Word2Vec은 다음 2가지 구조를 가지고 있다.
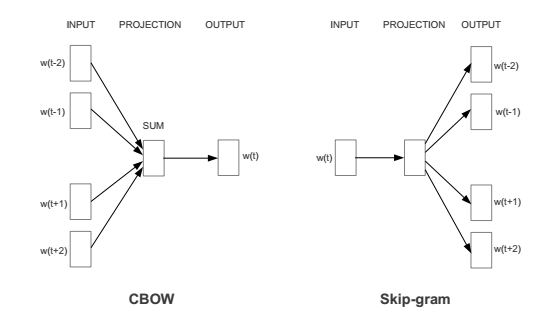
Continuous Skip-gram은 input이 t 번째 단어 1개이고, output이 t-2, t-1, t+1, t+2의 주변 단어들을 예측하는 모델이다. 상대적으로 더 빈도가 적은 단어를 잘 학습해서 성능이 살짝 더 좋다고 알려져있다.
Continuous Bag-of-words 은 반대로 input이 t-2, t-1, t+1, t+2의 주변 단어들이고, output이 t 번째 단어를 예측하는 모델이다. skip-gram보다 상대적으로 속도가 몇배 더 빠르다고 알려져있다.
이러한 구조에서 Word2Vec이 학습하는 것은 바로 각각의 단어들이 갖는 벡터값이다. 이 벡터값은 보통 200~300개정도의 엘리먼트를 갖는다. 그래서 결과적으로 어떤 벡터들을 단어들이 가졌을 때, 위에서처럼 다른 주변 단어들을 잘 예측할 수 있는가를 gradient descent로 optimization하는 알고리즘이다.
- Word2Vec의 알고리즘
구체적인 학습 알고리즘은 다음 동영상 강의에서 짧게 설명된다.
https://www.youtube.com/watch?v=vkfXBGnDplQ
간단히 요약하자면, 우선 input 단어가 추어졌을 때, output단어의 확률을 softmax로 예측한다. P(Word_out|Word_in)즉 이런식의 계산을 하게되고, 이것의 정답확률 값(크로스엔트로피)이 최대가되는 방향으로 학습을 할 것이다. # 크로스엔트로피가 맞는지, 이부분은 확실하지 않음.
그리고 일반적인 뉴럴네트워크에서의 softmax는 이렇게 생긴 식이다.

즉, X와 W벡터를 내적한 값들을 input으로 소프트맥스를 취함
그런데 word2vec에서의 소프트맥스는 아래와 같음.

즉 Vin과 Vout 벡터를 내적한 다음(내적은 두벡터의 similarity를 계산하는 것임), 이것들을 모든 단어벡터들에 대해 softmax를 취하는 것이다. 즉 모든 단어중에서, Vin과 Vout이 가까운 거리에 위치하는 벡터를 갖도록 하는 objective function을 계산하게 된다.
그런데 이때 단어들은 랜덤으로 초기화된 벡터형태로 바꾸어서 표현을 하게되고, 따라서 P(Vout|Vin) 이러한 확률 모델을 갖게된다.
이 상태에서 아마도 위에서의 크로스앤트로피(=라이클리후드와 같음)를 Vin 벡터의 각 성분으로 미분하여 각 엘리먼트가 움직여야하는 방향과 정도를 계산해서 gradient descent로 global minimum을 찾아간다.
이때 softmax는 계산량의 최적화를 위해 hierarchical softmax를 이용해서 V에서 logV수준으로 최적화를 하게된다. hierarchical softmax는 tree형태로 소프트맥스를 층층이 쌓은 것이다.
# Negative sampling:
Hierarchical softmax뿐만아니라, 이러한 softmax bottleneck의 문제를 해결할 수 있는 방법으로 negative samping을 이용한 softmax학습이 있다. 아이디어는 매우 간단하게, 마치 GAN에서의 discriminaotr처럼, 정답에 해당하는 데이터는 likelihood는 최대화하고, 정답이아닌 데이터의 likelihood는 최소화시키는 방법으로 학습하는 것이다.
http://alexminnaar.com/word2vec-tutorial-part-i-the-skip-gram-model.html
좋은 한글 블로그 : https://shuuki4.wordpress.com/2016/01/27/word2vec-%EA%B4%80%EB%A0%A8-%EC%9D%B4%EB%A1%A0-%EC%A0%95%EB%A6%AC/
- Word2Vec 코드 사용하기
우선 아래의 gensim라이브러리가 매우 구현이 잘되어있고, 최적화도 잘되어있다.
#기본 튜토리얼
http://rare-technologies.com/word2vec-tutorial/
# API 레퍼런스
https://radimrehurek.com/gensim/models/word2vec.html
# 라이브러리를 만들게된 배경과 속도 이슈
http://rare-technologies.com/deep-learning-with-word2vec-and-gensim/
내가 사용한 코드는 다음과 같다.
# This Python file uses the following encoding: utf-8
import os, sys
import gensim
import codecs
from gensim.models import Word2Vec
import json
# import modules & set up logging
import gensim, logging
def export_to_file(path_to_model, output_file):
output = codecs.open(output_file, 'w' , 'utf-8')
model = Word2Vec.load_word2vec_format(path_to_model, binary=True)
vocab = model.vocab
for mid in vocab:
#print(model[mid])
print(mid)
vector = list()
for dimension in model[mid]:
vector.append(str(dimension))
#line = { "mid": mid, "vector": vector }
vector_str = ",".join(vector)
line = mid + "\t" + vector_str
#line = json.dumps(line)
output.write(line + "\n")
output.close()
def parsing():
list_str = list()
for line in open(os.path.join('/opt/dhkwak_word2vec/word2vec_training','shakespeare.txt')):
list_str.append(line.split())
return list_str
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = parsing()
print(sentences)
model = gensim.models.Word2Vec(sentences, size=100, window=10, min_count=5, workers = 12,
ample=0.00001, iter=1000);
#model.save('dist_re.bin')
model.save_word2vec_format('word2vector.txt', binary=False)
이것은 이미 학습된 Word2Vec 의 bin파일을 txt형태로 바꾸어 주는 코드이다.
import gensim
import codecs
from gensim.models import Word2Vec
import json
def export_to_file(path_to_model, output_file):
output = codecs.open(output_file, 'w' , 'utf-8')
model = Word2Vec.load_word2vec_format(path_to_model, binary=True)
vocab = model.vocab
for mid in vocab:
#print(model[mid])
print(mid)
vector = list()
for dimension in model[mid]:
vector.append(str(dimension))
#line = { "mid": mid, "vector": vector }
vector_str = ",".join(vector)
line = mid + "\t" + vector_str
#line = json.dumps(line)
output.write(line + "\n")
output.close()
export_to_file('GoogleNews-vectors-negative300.bin','vector.txt')
여기서는 구글 뉴스 문서를 학습시켜, 약 1000억개의 단어를 학습시킨 bin 데이터를 제공한다.
https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit?usp=sharing
다른 데이터셋은 여기를 참조하면 받아볼 수 있다.
https://code.google.com/p/word2vec/
- bag of words
1. 한 문단에서 일단 유니크한 단어들을 모은다
2. 그다음 한 문장안에서 각 단어가 몇번 나왔는지 count를 하여, 문장 하나를 하나의 벡터로 표현한다.
ex) I like you and you like me -> I 1개, you 2개, like 2개 등등..
https://en.wikipedia.org/wiki/Bag-of-words_model
- 아래부분은 옛날 메모..
I eat pizza와 I ate pizza같이 쓰이는 문장을보고 eat과 ate과 유사한 의미를 가짐을 알아냄.
동시에 과거형에대한 방향 벡터 학습이 가능해짐.
objective : 단어의 벡터(Vin)을 주변 단어들로부터 직접적으로 학습한다.
처음에 이 벡터는 랜덤 이니셜라이즈 됨. 근데 이게 그레디언트 디센트로 학습됨.
방법은 이럼. eat의 벡터를 찾고싶으면, P(I|eat)과 P(pizza|eat)의 라이클리후드를 최대화 하는 것임.
즉 eat이 주어졌을 때 I가 나올 확률을 최대화하는 파라미터를 찾는다.
정확히는 P(I벡터|eat벡터) 임.
그런데 잘 보면 모든 단어는 2개의 벡터를 갖게됨. P(Vout|Vin)
근데 그중에서 우리가 진짜 쓰는 것은 Vin임
이 확률P(Vout|Vin)은 softmax(vin*vout)으로 결정함.
근데 실제로는 너무 단어개수가 많아서 hierachical softmax를 사용함
이렇게 트리구조를 사용하면 V에서 logV 로 연산량이 줄어듬
어쨌든 이 softmax를 Vin으로 미분해서 업데이트함
eat이 주어졌을 때 Hsoftmax로 I가 켜짐
tuple = 순서 + 집합 ex) t-2 t-1 t t+1 t+2
# Word2vec 이후의 여러 word embedding
'Research > Deep Learning & Application' 카테고리의 다른 글
| 딥러닝에서 쓸만한 다양한 Ensemble Method (0) | 2018.11.01 |
|---|---|
| Computer Vision Techniques (0) | 2017.03.15 |
| RNN의 Vanishing Gradient와 Exploding Gradient (0) | 2015.07.08 |
| CNN, Spectrogram 을 CNN으로 학습 (0) | 2015.04.22 |
| TDNN, RNN, LSTM, ESN (0) | 2015.04.15 |
댓글