Markov Assumption(=Markov Property) : 직전 사건에의해서만 현재 사건이 영향을 받는 속성
Chain : discrete한 Time Sequence 사건
Markov Chain : Markov Assumption 을 만족하는 Chain
Monte Carlo Method : 다음과 같이 여러개의 표본을 추출해서 전체적인 분포를 파악하는 방법론
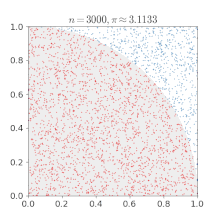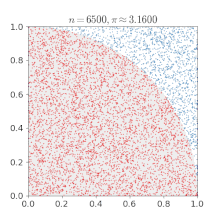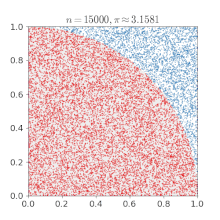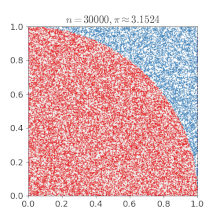
Sampling : 해당 모델을 만족하는 데이터를 생성, 추출해내는 것. 단 그 모델의 확률 분포에 비례하여 확률 밀도가 높은 곳에서 그에비례하게 더 많은 데이터가 나오도록 추출해야 한다.
Markov Chain Monte Carlo : Markov Chain에서 샘플링을 하기위해 Monte Carlo Method를 써서 확률 분포가 반영된 데이터를 샘플링하는 것. 여기서의 Markov는 샘플링을 Markov Chain으로 하는 의미임.
(Markov Random Field에서의 Markov는 그래프의 노드들이 서로 마르코프 프로퍼티를 갖는의미인듯)

Detailed Balance : MCMC에서 뽑은 샘플이 P(X)의 분포를 충분히 근사하기 위한 조건. P(X'->X)/P(X->X')=1 이면 만족하며, Ergodicity 라는 개념 또한 관련이 있다. 간단히 말하면 확률 분포가 연속적이고 섬처럼 동 떨어진 분포가 있지 않는 일반적인 경우를 말한다.
Rejection Sampling : MCMC 알고리즘 중 가장 기본적인 샘플링 기법. 랜덤하게 (Uniform 하게) 하나의 데이터를 추출한 다음, 그것의 확률값을 계산하여 그 확률만큼 Accept하고 나머지는 Reject시키는 방법. (당연히 이렇게하면 확률값이 큰 곳의 샘플들은 많이 뽑히고, 확률값이 적은 곳의 샘플들은 잘 뽑히지 않는다. 그러나 이 방법은 확률분포가 매우 넓고 길게 퍼져있는 공간에서는 버려야하는 샘플이 너무 많아 시간 효율이 좋지 않다.)
Metropolis-Hastings : 조금 더 개선된 MCMC 알고리즘의 하나로 샘플링을 한 번 한다음, 다음 샘플에대해서 Accept 할지를 min(1, P(X')/P(X)) 의 확률로 결정하는 방법. X'은 다음에 샘플링하기 위해 랜덤하게 (Uniform하게) 뽑아본 샘플이다. min(1, P(X')/P(X))을 해석해보면, X'에서의 확률이 기존 샘플 X에서의 확률보다 크면 무조건 샘플링을 하는 것이고(1이 선택되므로),X'의 확률이 더 작은 경우 그에 비례하여 Reject를 하는 방법이다. 이것은 Detailed Balance를 만족시키면서 보다 빠른 방법이다.
그러나 Metropolis-Hastings의 경우도 고차원으로 갈 수록 한 샘플에서의 확률값이 0으로 점점 가까워지기 때문에 Accept Ratio가 매우 낮아져 시간 상 비효율적이다.
(고차원에서도 어떤 확률 분포의 합은 결국 1이되어야한다. 그러나 차원이 커질수록 그것을 구성하는 분포도 차원에따라 확장되어 퍼질 수밖에 없다.)
Gibbs Sampling : Metropolis-Hastings의 단점인 고차원에서의 느린 샘플링을 해결한 MCMC 알고리즘. 구현이 쉽고 간편하며, 실행속도도 빨라 널리 사용되는 샘플링 방법이다.
맨 처음 하나의 Initial 한 샘플을 랜덤하게 정한다음, 그 샘플에서 변수를 1개씩, 즉 1개 차원씩 번갈아가면서 정하는 방법.
이것은 Xi ~ P(Xi|X-i) 로 표현하며, 의미는 Xi라는 i번 째 변수 하나를 결정할 때, i를 제외한 나머지(X-i) 변수들을 이용해서 결정하는 것이다.
만약 L 차원에서의 확률 분포라면, 1~L까지의 변수들을 하나씩 샘플링 한다음, 다시 1~L까지를 또 샘플링하고 이것을 계속해서 반복한다. 그렇게 만든 샘플들이 쭉 있으면, 그것들을 다시 일정한 간격으로 택하여 최종 샘플링을 완성한다.
Gibbs Sampling은 고차원의 영역을 빠르게 여기저기 왔다갔다하면서 샘플들을 뽑기 때문에 딥러닝 등에서 자주 쓰인다.
(Gibbs Sampling의 Binary 에서 예시)
1-1 : [1,0,1] // Initial 샘플로, 랜덤하게 정해진 것이며, 굵게 칠해진 숫자"1"을 0으로 바꿀지, 그대로 1로 놓을 지를 나머지 두 변수 0, 1의 확률을 이용해서 계산한다.
1-2 : [0,0,1] // 다시 두번 째 변수인 0에대해서 결정 한다. 물론 확률적인 것으로, 0->0이 될 수도 있고 0->1이될 수도 있다.
1-3 : [0,1,1] // 마지막 세번 째 변수인 1에대해서 정한다. 이번엔 1->1로 변하지 않았다.
(3차원 변수이므로, 3회가 지날 때 마다 전체 데이터를 샘플링한다.)
2-1 : [0,1,1] // 다시 마지막 상태에서부터 이어서 첫번 째 변수부터 시작한다.
2-2 : [1,1,1]
...
이렇게 1000사이클을 돌아 총 1000*3개의 결과가 완성되었다고 해보자, 그러면 이 3천 개의 데이터셋에서 일정한 간격(N차원 일 경우, N번 째 간격)으로 데이터를 선택하여 최종적인 샘플링을 완성한다. 그 이유는 위와 같은 과정이 N 번 거쳐야만, 모든 차원에 대해 변화가 이루어지기 때문이다.
Gibbs Sampling은 일종의 현재 상태에서의 변수들의 상태를 체크해보고자 하는 방법으로 쓰일 것 같다는 느낌이다. 물론 활용 범위가 매우매우 커서 공학적으로 안쓰이는 곳이 없는 것 같다.
http://enginius.tistory.com/296
고급이론 :
Gibbs sampling에서는 proposal distribution 이 그 확률 분포 자체의 conditional distribution이다. RBM같은 경우 이 conditional 분포자체가 gaussian혹은 베르누이 분포이기 때문에 이 자체에서도 바로 샘플링이 가능하며, 이것의 의미는 N차원의 공간에서 1축씩 이동할 때, conditional distribution을 통해서 샘플링을하여 한 축씩 이동하는 것을 의미한다.
그런데 만약 gibbs sampling에서의 conditional distribution자체만으로 proposal distribution으로 사용이 불가능할 때, 즉 샘플링이 불가능한 분포인 경우 이 1개의 축을 이동하는 과정에서도 metropolis-hastings 같은 방법을 사용해야만 한다. 즉 어떻게 보면 깁스샘플링은 1축씩 이동하는 어떤 메타 방법론이라고 볼 수도 있다.
그리고 만약 gibbs sampling을 2차원의 변수에 대해서 할 때, 2개의 모드가 있는데 이 두개의 모드가 x1과 x2의 대각선 방향으로 아주 멀리 서로 위치해 있다면, gibbs sampling만으로는 절대 다른 모드로 넘어갈 수가 없다. 왜냐하면 1축씩 이동하는 방식으로는 현재의 모드밖을 넘어갈 확률이 0이기 때문이다.(대각선에 위치하므로 1개의 변수만 사용해서는 확률이 0이됨)
그러나 아주 고차원 공간에서는 이런식으로 모든 축에대해서 걸리지 않는 모드가 존재할 확률이 매우 낮아지고, 반드시 어느 한 축에서는 다른 모드의 확률이 존재하게 된다. 그래서 고차원 공간에서는 이렇게 1개의 축이라도 걸리면, 이 축을 통해서 다른 모드로 넘어가는 것이 가능하다. 그래서 gibbs sampling이 고차원 공간에서 아주 빠르게 효과적으로 잘 동작한다고 볼 수 있다.
'Research > Machine Learning' 카테고리의 다른 글
| Deep Belief Network (0) | 2014.08.01 |
|---|---|
| RBM, Contrastive Divergence (4) | 2014.07.23 |
| P, NP, NP-Complete, NP-Hard, 시간 복잡도 (0) | 2014.07.22 |
| Dimension Reduction, Curse Of High Dimensionality (0) | 2014.07.18 |
| Linear Discriminant Analysis (0) | 2014.07.18 |

댓글