텐서플로우는 잘못사용하면 정말 정말 정말 느리다.
기본적으로 주어지는 공식 예제는 속도 최적화를 전혀 고려하지 않은 예제이기 때문에, 내가 아무리 비싸고 좋은 GPU를 사용하더라도, 저렴한 GPU에 비해 심각하게 느릴 수 있다. 이에 대한 여러가지 분석과 해결법을 정리해본다.
1. GPU Utilization 분석
먼저 내가 만든 TensorFlow 모델이 과연 얼마나 최고의 효율로 GPU를 사용해서 돌아가고 있는지 확인하자.
그래서 nvidia-smi 혹은 nvidia-smi -a 를 입력하여 Volatile GPU-util 이라는 항목을 볼 수 있는데 이것의 의미는 최근 1 초동안 busy 상태였던 core의 비율을 의미한다.
http://stackoverflow.com/questions/5086814/how-is-gpu-and-memory-utilization-defined-in-nvidia-smi-results
그런데 만약 내가 돌리는 process에서 이 GPU-Util이 낮다면, 이는 GPU 성능을 최대로 사용중이 아님을 의미한다. 예를 들어 GPU-Util이 10% 밖에 안나온다면? 이는 GPU성능이 10%만 사용중이라고 생각해볼 수 있다.
https://groups.google.com/a/tensorflow.org/forum/#!topic/discuss/SXWDjrz5kZw
2. Profiling
이러한 문제가 발견되면 어떠한 원인에서 병목이 생기는 지 분석해야한다.
2.1 CPU연산을 사용하는 오퍼레이터 확인하기
세션을 생성할 떄 다음과 같은 옵션을 추가해서, 실행을 시켜보자.
그러면 처음에 세션을 생성하면서 어떠한 오퍼레이션이 gpu 혹은 cpu에서 실행이 되는 것인지 로그를 쭉 찍어준다. 이 중에서 cpu오퍼레이션이 할당된 연산을 자주 실행할 경우 매우 심각한 성능 저하를 일으킬 수 있다. 대표적인 예가 TensorBoard를 위해 사용하는 summary_writer와 saver를 이용한 파라미터 저장이다. 이러한 오퍼레이션은 당연히 cpu를 통해서 파일을 액세스하기 때문에 자주 실행할 경우 cpu와 gpu 병목이 생길 수밖에 없다.
2.2 TensorFlow에서 공식으로 지원하는 Profiling 툴을 이용해 어떤 오퍼레이션이 많은 시간을 쓰는지 분석하기
TF Profiler : https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras
좀 더 세밀하고 상세한 분석을 위해 Profiler를 사용하여, 어떤 부분의 operation에서 시간이 많이 걸리는지 visulization하여 볼 수 있다.
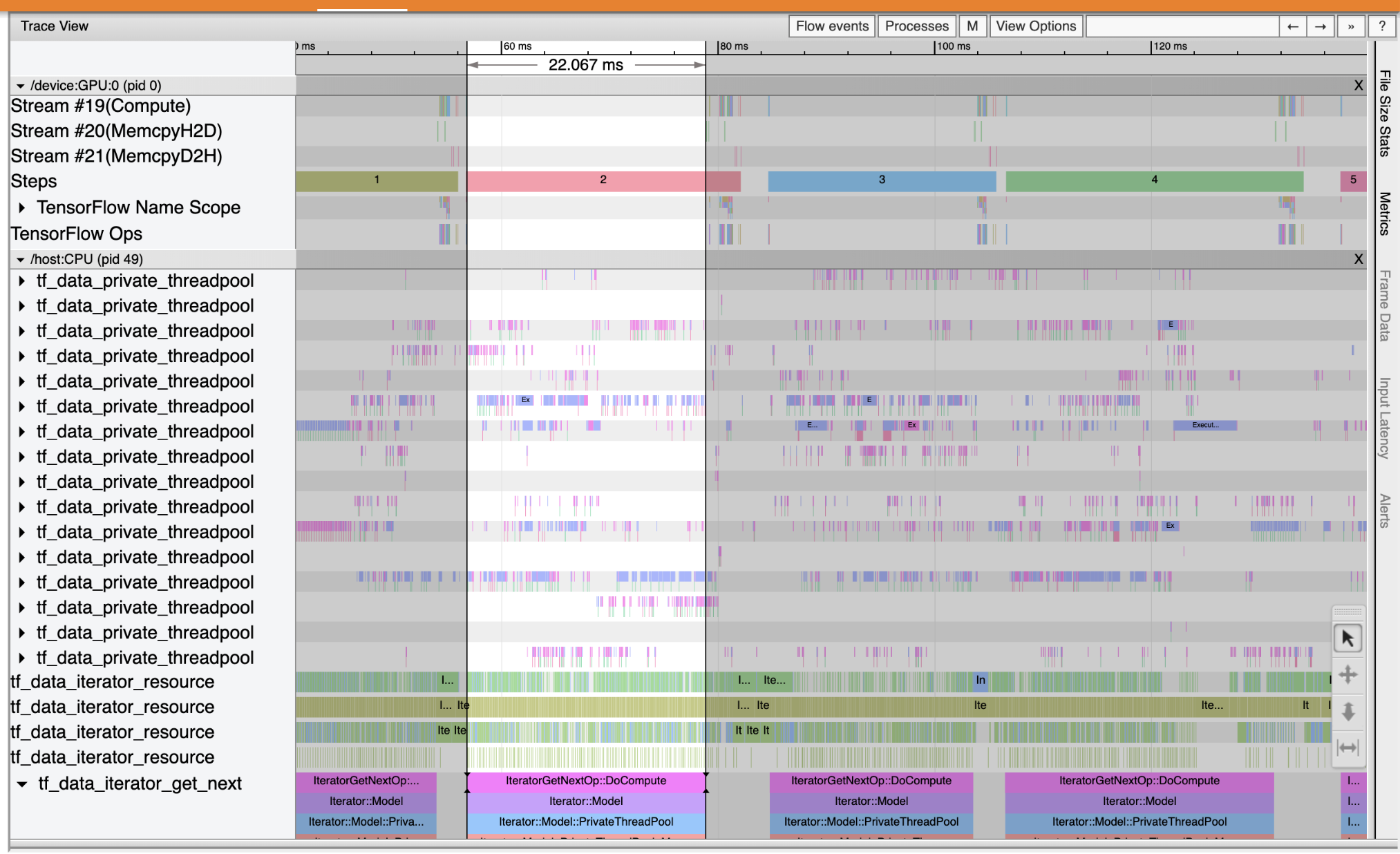
일단 간단한 사용방법은 아래와 같다.
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64
(혹은 sudo apt-get install libcupti-dev)
run_metadata = tf.RunMetadata()
output = sess.run([output],
feed_dict = { ~~~~ },
options=tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE),
run_metadata=run_metadata)
from tensorflow.python.client import timeline
trace = timeline.Timeline(step_stats=run_metadata.step_stats)
trace_file = open('timeline.ctf.json', 'w')
trace_file.write(trace.generate_chrome_trace_format())
https://github.com/tensorflow/tensorflow/issues/1824#issuecomment-225754659
3. feed_dict의 사용을 최소화
또한 feed_dict를 이용해서 sess.run을 할 경우 매번 run을 실행할 때마다 cpu RAM에서 gpu RAM으로 데이터 전송을 하게된다. 그런데 이는 매우 큰 시간 병목을 가지고 있다. 그래서 우리는 가능한 feed_dict가 아니라 다른 방법을 사용해야한다.
4. session.run() overhead
기본적으로 session.run()을 실행할 경우 run time에 cuda compiling을 하게 된다. 따라서 매우 짧은 주기로 반복해서 session.run()을 실행하면 오버헤드가 상당하기 때문에, 이를 주의하여 코딩해야한다.
# 그이외 TF 속도 최적화와 관련된 글
현재의 글은 구버전의 TF를 대상으로 하기 때문에, 이러한 이슈가 최신 버전의 TF에서는 고쳐졌는지 확인 할 필요가 있다.
https://github.com/tensorflow/tensorflow/issues/2444
https://github.com/tensorflow/tensorflow/issues/5516
https://github.com/tensorflow/tensorflow/issues/120
http://stackoverflow.com/questions/33956956/counter-on-gpu-insanely-slow-compared-to-default-counter
'Development > for Machine Learning' 카테고리의 다른 글
| Github Markdown 사용법 (0) | 2017.08.21 |
|---|---|
| Jupyter Notebook (0) | 2017.05.23 |
| TensorFlow 프로그래밍 (0) | 2016.09.13 |
| 빅데이터 플랫폼 (0) | 2015.04.13 |
| Practical Theano Tutorial (0) | 2015.03.11 |

댓글