Advanced Gradient Descent Method
Advanced Gradient Descent Method (고급 경사 하강 법)
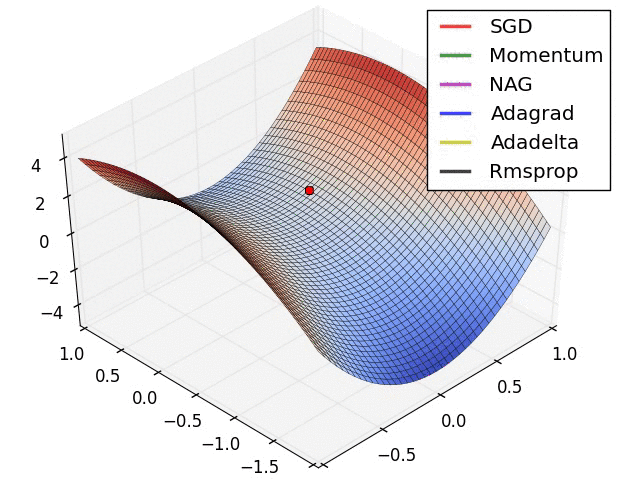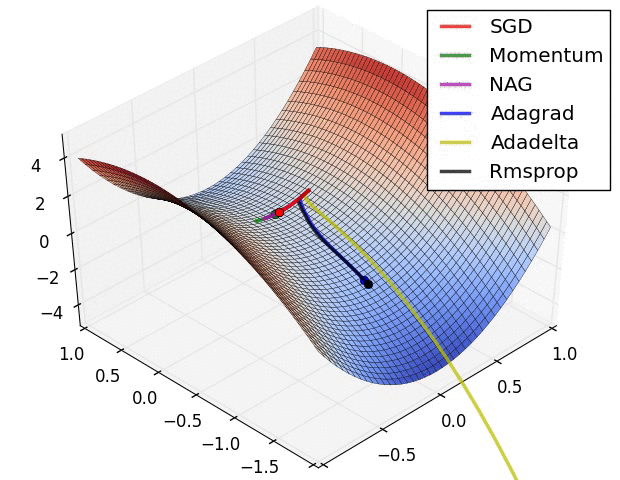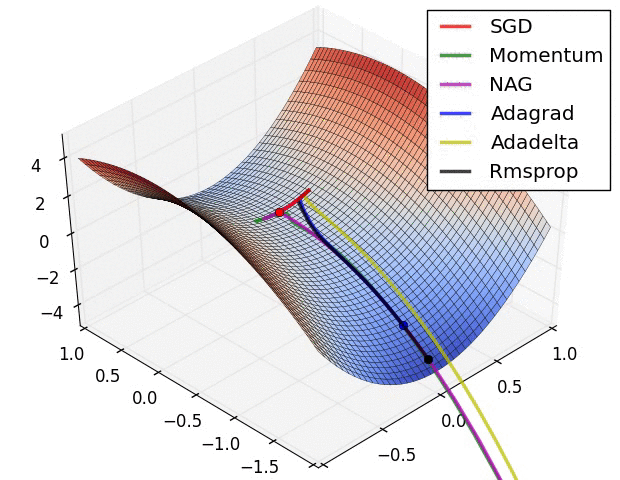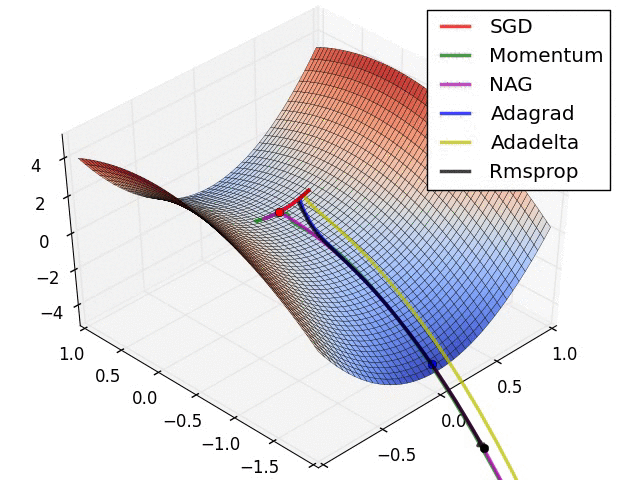
위에서 소개된 그림은 특정한 landscape에서의 각각의 optimizer들의 학습 속도를 표현 한 것이다. 보기에는 Adadelta가 최고인가하고 생각 할 수 있겠지만, 문제 상황에 따라 잘하는 경우도 있고, 못하는 경우도 있으므로 문제 상황에 맞게 잘 선택해야한다.
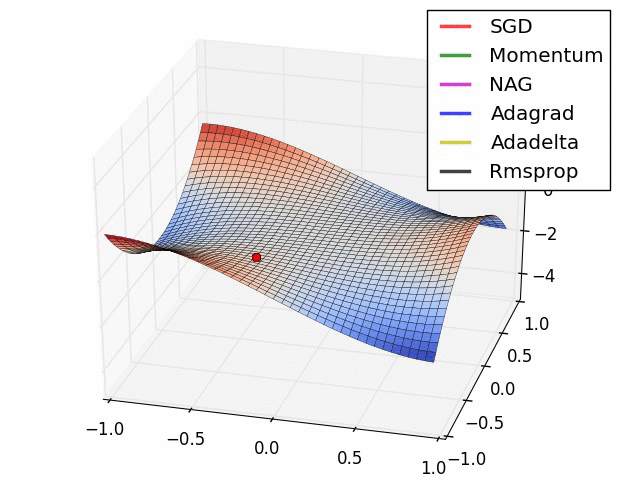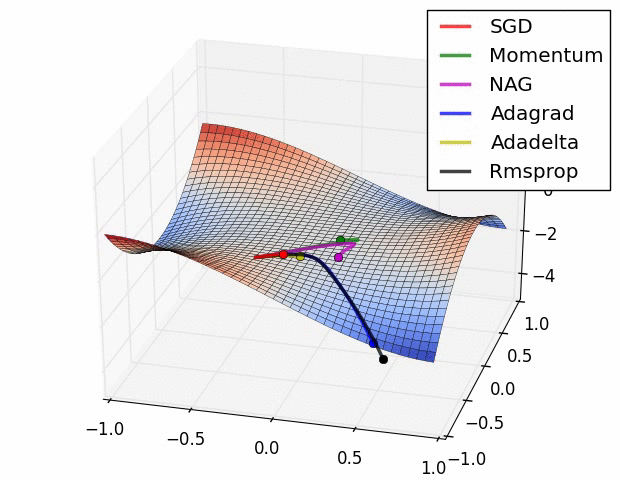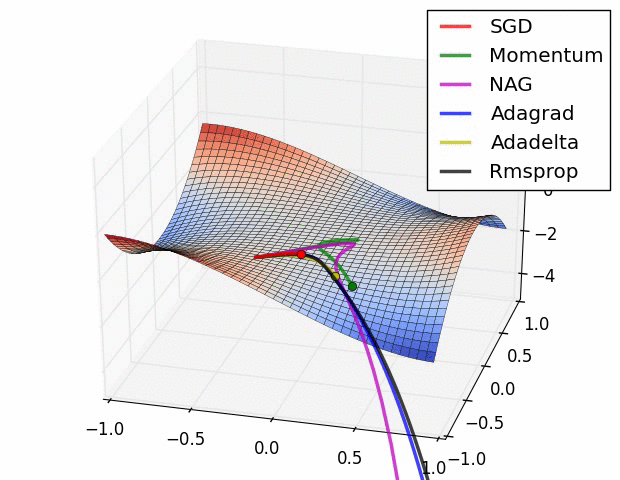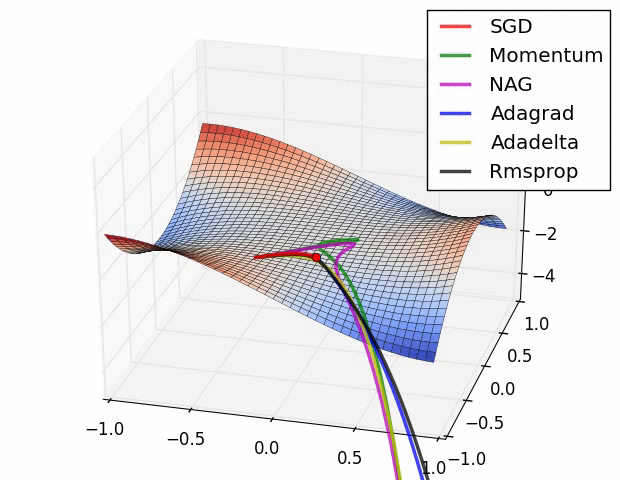
위의 이미지는 특히 Rmsprop와 Adagrad가 좋은 성능을 보인다. 뉴럴넷의 W와 같은 고차원의 공간에서는 이러한 saddle point가 매우 많아 문제가 되는 것으로 알려져있다. 따라서 이 두가지 옵티마이저를 선택하는 것은 좋은 방법이다.
요즘에는 Adam이라는 optimizer가 기본으로 쓰는 경우가 많고, 경우에 따라 non-stationary가 심한 문제(강화학습 등)에서 RMSprop를 선택하는 경우가 많다.
-
GD (Gradient Descent): GD는 가장 기본적은 뉴럴넷의 학습 방법으로, 전체 데이터에 대한 Error함수를 Weight로 미분하여 계산한 각 W 파라미터에 대한 gradient를 이용하여 Weight를 업데이트한다. 이 때 얼만큼의 gradient를 사용할지 결정하는 값을 learning rate라고 하는데, 이 값에 따라 local minima에 빠지거나 발산하는 경우가 있다. 또한 전체 데이터에 대한 계산을 한 뒤에 W를 업데이트하기 때문에, 계산량이 너무커 W가 optimal을 찾아가는 속도가 느려 현재는 거의 쓰이지 않고 있다. Batch Learning이라고도 부른다. 또한 gradient descent는 기울기가 양수(+)이면 w를 음수(-)방향으로 이동시켜야 하므로, 기울기의 반대 부호로 움직인다고 볼 수 있다.
W' = W − λ f'(W) ( λ 는 learning rate이다.)
SGD (Stochastic Gradeint Descent): SGD는 위에서 GD가 갖는 너무 큰 계산량 문제를 해결하기 위해 전체 데이터중에서 랜덤하게 추출한 1/N의 데이터만을 사용해 훨씬 더 빠르게, 자주 업데이트하는 방법이다. 이 때 추출한 1/N의 데이터를 Minibatch라고 부르며, 이 데이터가 전체 데이터의 분포를 따라야만 제대로 된 학습이 가능하다. 만약 이 데이터가 전체 데이터의 분포를 따르지 않고, 계속 분포가 바뀌는 non-stationary한 경우를 online learning이라고도 부른다.
전체 데이터를 잘 섞어서, 너무 작지 않은 크기로 N 등분하면, 계산량이 1/N 배가되어, 빠르게 Weight를 업데이트할 수 있어, 이론상 N배 더 빠른 학습이 가능하다.
추후 SGD에서 각 Minibatch 분포가 매번 약간씩 달라지는 noise를 internal covariate shift라고 부르며, 이를 해결하기 위한 방법으로 batch-normalization이 등장한다.
Downpour SGD: Downpour SGD는 DistBelif라는 구글의 모델, 데이터 병렬화 학습 모델에서 소개된 방법이다. 간단히 말하면 여러개로 모델을 쪼개어, 여러개의 머신에서 동시에 학습을 하는데 이 때 여러 모델들에서 계산된 gradient를 평균내서 각각의 모델에 적용하는 방법이다. 이렇게 해도 충분히 전체 데이터와 모델에 대한 근사적인 학습이 가능하다고 하다.
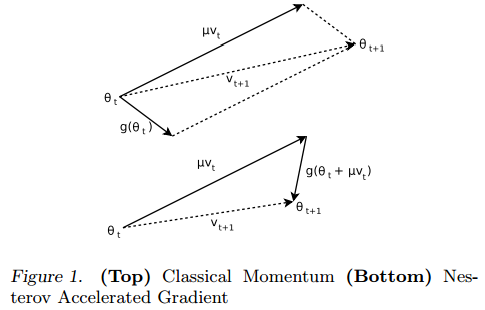
Per-dimension learning rate: 이 원리는 Momentum 및 기타 여러 advanced optimizer들의 핵심을 관통하는 개념이다. 짧게 설명하자면 각각의 차원마다 서로 다른 learning rate를 사용해야만 더 빠르게 saddle point를 벗어날 수 있다는 것이다. 예를 saddle point에서 long narrow valley 방향으로의 gradient값은 매우 작지만, 이쪽 방향으로 빨리, 많이 학습해야만 이 saddle point를 벗어날 수가 있다. 따라서 이쪽 방향으로의 learning rate는 커야한다. 이러한 개념은 아래 소개되는 advanced method에서 공통적으로 통하는 개념이다.
자세한 내용은 아래 글 참고하기 바란다.
The heuristic annealing procedure discussed above modifies a single global learning rate that applies to all dimensions of the parameters. Since each dimension of the parameter vector can relate to the overall cost in completely different ways, a per-dimension learning rate that can compensate for these differences is often advantageous. When gradient descent nears a minima in the cost surface, the parameter values can oscillate back and forth around the minima. One method to prevent this is to slow down the parameter updates by decreasing the learning rate. This can be done manually when the validation accuracy appears to plateau. This gives a nice intuitive improvement over SGD when optimizing difficult cost surfaces such as a long narrow valley. The gradients along the valley, despite being much smaller than the gradients across the valley, are typically in the same direction and thus the momentum term accumulates to speed up progress. In SGD the progress along the valley would be slow since the gradient magnitude is small and the fixed global learning rate shared by all dimensions cannot speed up progress. These oscillations are mitigated when using momentum because the sign of the gradient changes and thus the momentum term damps down these updates to slow progress across the valley.

Adagrad는 러닝레이트를 다음과 같은 노멀라이제이션 L2 term으로 나누어주는 것이다.

RMSProp: Non-stationary 한 데이터를 학습시킬 때 많이 사용한다.

http://sifter.org/~simon/journal/20150415.html
http://climin.readthedocs.org/en/latest/rmsprop.html#tieleman2012rmsprop
http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdfRMSProp with momentum:
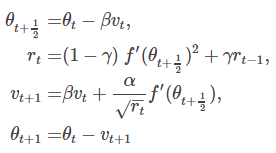
Adam: 최근의 딥러닝에서 가장 많이 default로 사용되는 optimizer이다.
The method combines the advantages of two recently popular optimization methods: the ability of AdaGrad to deal with sparse gradients, and the ability of RMSProp to deal with non-stationary objectives.
http://arxiv.org/pdf/1412.6980v8.pdf
-
Learning Rate Decay : 위에서 살펴본 여러 optimizer들 또한 어느정도 learning rate의 스케일을 조절하는 기능은 있다. 그러나 practical 한 관찰 결과 이들의 기능은 각 dimension 마다 움직여야할 학습률의 비율을 찾아주는 효과가 강하다. 그래서 scaling을 따로 해주는 기능을 추가로 구현하는 것이 더 성능을 좋게할 때가 많다.
간단한 예를 들자면, 아래와 같은 Loss - Weight space에서는 0.1의 learning rate로 학습을해서 점점 더 낮은 지역을 찾아가는데, 문제는 이를 충분히 학습시킨 Loss - Weight space역시 아래의 모양과 동일하게 울퉁불퉁한 landscape을 가지고 있다는 점이다. 즉 마치 프랙탈 처럼, 충분히 학습을 해서 space를 더 좁은 공간으로 파고 들어도 마찬가지로 동일한 모양의 space가 나온다는 것이다. 그러면 당연히 학습을 할수록 learning rate의 크기는 확대된 공간 만큼 줄어들어야 할 것이다. 이러한 이유 때문에 learning rate decay가 필요하다.

그러므로 Adam을 사용함과 동시에 특정한 스텝마다 learning rate를 1/2씩 exponential하게 줄여주는 기능을 같이 사용하는게 더 좋은 성능을 보인다.
그러나 언제 learning rate decay를 해야할지 결정하는 것은 굉장히 어렵다. 단순히 일정 iteration마다 decay를 하게되면 문제마다 그 iteration길이를 조정하는 것이 다르기 때문에 쓰기가 매우 힘들다. 그래서 가장 무난 방법은 Loss가 더이상 감소하지 않고 장시간 수렴해버리거나, 오히려 Loss가 일정시간 증가하는 것이 관찰될 때 learning rate decay를 해주는 것이 좋아 보인다.
Weight decay :
Weight의 크기에 비례하여, weight 업데이트속도를 더 낮추는 regularizer. L2 regularization과 특정한 조건에서 동치일 수 있다.
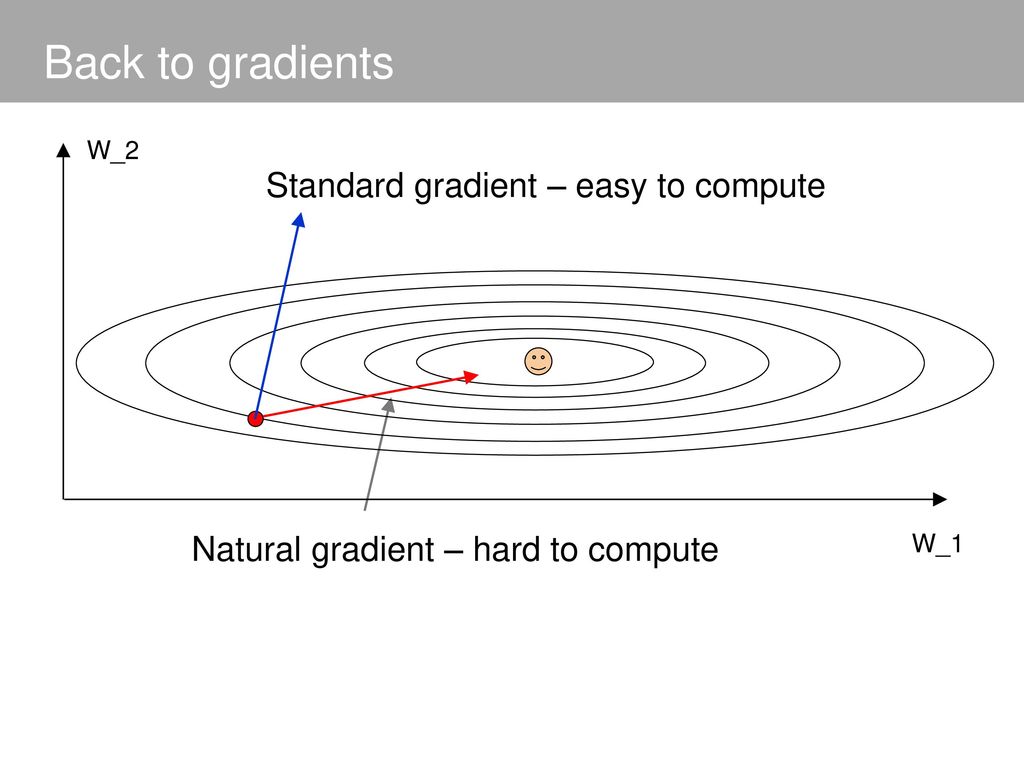
즉 "확률 분포"를 좋게 만드는게 목표인데, 그걸 단순히 Loss값에 대한 미분으로 얻은 gradient를 업데이트한다고 해서 정말로 좋은 분포가 될 것인가(물론 Loss는 줄어들 겠지만..)
일반적인 sgd를 사용할 경우 미니배치 샘플에 따라 매우 불안정한 학습과정을 거칠 수 있기 때문에 더욱이 문제가 됨. 그래서 natural gradient를 사용하여 분포가 안정적으로 수렴할 수 있게 해줌.
뉴턴메서드는 에러 함수에 대한 2차 테일러 근사가 좋고, 에러 함수가 w' 근처에서 quadratic하다면, w' 근처의 local minima를 한 번에 찾을 수 있다는 아이디어이다. 이는 곡률이 작은 즉, 완만한 형태의 에러 함수에서는 굉장히 빠른 속도로 학습을 할 수 있고, 반대로 곡률이 큰 곳에서는
- 그 이외 최신 구현되어 유행을 타는 optimizer를 아래에서 확인할 수 있다.
- 다음 블로그에 매우 좋은 내용이 잘 정리됨!
http://sebastianruder.com/optimizing-gradient-descent/
,