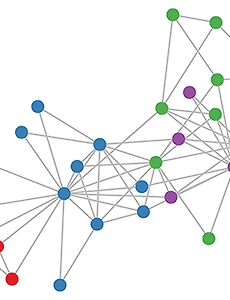
2020/0114 Graph Neural Networks 0. Convolutional Neural Networks의 Graph 해석 Karate club graph, colors denote communities obtained via modularity-based clustering (Brandes et al., 2008) 위와 같은 그래프 형태의 데이터를 학습하기 위한 가장 좋은 네트워크 아키텍쳐는 무엇일까? 바로 Graph Convolutional Networks이다. GCN은 널리 알려진 Convolutional Neural Networks에 Adjacency Matrix를 도입하여 보다 데이터의 structure를 보다 일반화된 형태의 그래프로 정의한 것이다. Adjacency Matrix란 아래와 같은 graph가 있을 때, 각 node간에 연결(.. 2020. 1. 30. 작은 따옴표, 아포트트로피, 그레이브 악센트 구분 아포스트로피: I'll 같이 말을 생략하거나, Google's와 같은 소유격에 사용되는 특수문자.보통 작은따옴표를 사용한다.https://ko.wikipedia.org/wiki/%EC%95%84%ED%8F%AC%EC%8A%A4%ED%8A%B8%EB%A1%9C%ED%94%BC Quote: 따옴표. 마찬가지로 작은따옴표나 큰따옴표를 사용한다.He said, "I can't swim." Grave Accent: 특정한 발음기호를 가진 알파벳을 나타낼 때 사용한다.ESC아래에 있는 ` 키로 입력한다. https://en.wikipedia.org/wiki/Grave_accent 2020. 1. 30. 다양한 Convolution Layer Convolution기본적으로 convolution layer는 fully connected layer에서 spatial(이미지의 가로세로) 영역을 잘게 쪼개고, 그만큼 weight sharing을 시킨 아키텍쳐이다.그러나 feature dimension(=channel, depth)에 대해서는 여전히 fully connected를 유지하고 있다. 즉 모든 input channel을 섞어서 각각의 output channel로 연결하는 과정이 fully connected라는 의미이다. 수식으로 말하자면 input channel이 256 dim이고 output channel이 128 dim이라면, feature dim에 대한 weight matrix는 [256x128]로 fully connected 이다. .. 2020. 1. 30. Bayesian Inference Machine Learning 에서 궁극적으로 추구하는 목표는 P(X'|X) 를 알아내는 것이다. (X' : 예측하고자 하는 데이터 , X : 기존에 관측된 사건의 데이터) 즉, 기존에 관측된 사건의 데이터 X를 이용해서 앞으로 일어날사건 X'에 대해 예측하는 것이다. 만일, X 없이 그냥 P(X')를 계산한다는 것은 기존에 일어난 사건 데이터 전혀 고려하지 않고, 오직 수학적 모델만으로 확류를 계산하겠다는 의미이다. 이는 machine learning이라 부를 수 없고, 일반적으로 데이터 X를 고려할 때보다 훨씬 부정확한 확률 추론을 하게된다. 좀 더 직관적인 예를 들면, 두개의 박스 A와 B에서, A에는 빨간공이 99%, B에는 파란공이 99% 들어 있다고 하자. 이때 한 사람이 무작위로 두 박스중 .. 2020. 1. 29. Advanced Supervised Learning Advanced Supervised Learning Active LearningUnlabeled data에 대해 MC dropout을 inference를해서 confidence를 측정해서 낮은것부터 labeling한다.똑같은 방법으로 loss prediction을 해서 loss가 큰 것부터 labeling할 수도 있다. Online Service Data + Active Learning감독학습 모델의 실서비스를 하면서 계속해서 들어오는 input x에 대해, 모든 데이터를 전부 labeling할 수는 없다. 따라서 이 중에서 어떤 데이터를 labeling할 지 우선순위를 정해야하는데 이 때 active learning이 필요하다. Multi-task Learning에서 난이도에 따른 Overfitting.. 2020. 1. 28. Librosa, Numba 에러 해결 Librosa install하기pip install librosa혹은conda install -c conda-forge librosaRuntimeError: cannot cache function '__jaccard': no locator available for file '/opt/conda/lib/python3.6/site-packages/librosa/util/matching.py'원인0.7이 넘어가는 librosa에서 numba cache를 사용하는데, numba cache dir에 대한 권한이 없어서 생기는 문제이다, https://github.com/numba/numba/issues/4032https://github.com/ska-sa/montblanc/issues/253 해결책: 다음 셋 중.. 2020. 1. 23. 효율적인 ML 프로젝트 개발 환경: Sublime과 Pycharm 필수 규칙 1. 무조건 editor가 아닌 IDE를 사용해야한다. pycharm을 쓸 때랑 sublimetext를 사용할 때의 생산성 차이는 압도적이다.(특히 refactor) 1. 무조건 local에서 바로 실행할 수 있어야한다. 즉시 응답하는 빠른 run이 가능해야만 손쉽게 디버깅을 할 수 있다. local run은 단순히 pytorch cpu에서 실행해도 전혀 상관이 없다. 서버에서 실행해야하는 경우도 가능하면 toy환경을 local로 가져오는 것이 좋고, 그마저도 힘들다면 sftp를 이용해서 remote의 코드를 pycharm으로 수정하도록 한다. 기계학습의 경우 데이터의 아주 일부분이라도 프로젝트에 내장시켜서 local run이 가능하게 해야한다. 1. 내가 사용하는 환경을 docker로 한번 .. 2020. 1. 17. Z-shell ( zsh ) 사용하기 zsh ( z-shell ) zsh은 bash shell에서는 제공하지 않는 사소하지만 정말 편리하고 우아한 기능들을 제공하는 shell이다. zsh 설치과정1. sudo apt-get install zsh 2. oh-my-zsh 설치 sh -c "$(wget -O- https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh)" 3. zsh-syntax-highlighting git clone echo "source ${(q-)PWD}/zsh-syntax-highlighting/zsh-syntax-highlighting.zsh" >> ${ZDOTDIR:-$HOME}/.zshrc source ./zsh-syntax-hig.. 2020. 1. 17. Numpy Optimization and Parallelization 1. 문제상황 [100000, 1000] 크기의 matrix를 10만차원 축으로 cumsum을 했더니 약 2.3초가 걸려서 이를 더 빠르게 하고싶음. 기본 실험: 해당 matrix에 대해서 np.sum과 np.cumsum 을 수행해봄. 3번과 4번 cell에서는 cumsum을 한번에 모든 dim에대해 한것과 하나씩 바꿔가면서 한 실험 결과임 cumsum의 경우 메모리에 writing하는 연산이 많아 sum보다 많이 느림. 그런데 3번과 4번에서 속도차이가 나는 것이 이상해서, inplace cumsum으로 바꾸니 속도가 동일해짐. 2. C로 최적화?여기서 더 빠르게 하기 위해, Numpy를 C로바꾸면 더 빨라질까? 결론은 Numpy가 C보다 더 빠르다,. Python VS C https://medium... 2020. 1. 17. The Bitter Lesson 번역 The Introduction of Reinforcement Learning의 저자로 유명한 Richard Sutton의 2019년 5월 13일에 올라온 AI에 대한 글을 번역해보았다. (역자: 곽동현, 윤상웅) The Bitter Lesson 씁쓸한 교훈 70년간의 AI연구로부터 깨달을 수 있는 가장 큰 교훈은 바로 계산을 이용하는 일반적인 방법론이야말로 궁극적으로, 큰 격차를 두고도 가장 효율적이라는 것이다. 이에 대한 궁극적인 이유는 바로 무어의 법칙, 더 일반화해서는 유닛 당 계산 비용이 지수적으로, 꾸준히 감소하고 있기 때문이다. 대다수의 AI 연구는 agent가 사용가능한 계산자원이 일정하다는 조건에서 행해졌으나(이 경우 인간의 지식을 최대한 이용하는 것이 오직 유일한 성능 향상의 방법일 것이.. 2020. 1. 17. Pytorch 개발 팁 Pytorch 설치하기 Pytorch를 설치하는 가장 간편한 방법은 conda를 이용하는 것이다. conda의 설치 및 사용 방법은 다음을 참조하길 바란다. conda가 이미 있다면 아래의 명령을 실행하면 최신 버전의 pytorch가 설치된다. 이때 -c 옵션을 주는 것이 중요하다. 이는 pytorch채널에서 해당 라이브러리를 탐색하여 설치한다는 의미이다. 다른 pytorch 버전을 설치하고자하면, 공식 홈페이지를 참조하자. conda install pytorch -c pytorch Multi-GPU 환경에서 특정 GPU만 default로 사용하기 bash에서 다음을 실행 export CUDA_VISIBLE_DEVICES=4 혹은 python에서 다음을 실행 os.environ["CUDA_VISIBLE_.. 2020. 1. 16. 블로그 글쓰기 규칙 Step 0. 기본 설정- 항상 문단 간격 없음으로 작성한다.- Markdown 보다는 tistory 기본 에디터를 적극 활용한다.- 그이외의 경우 Bold는 사용 가능하나, 글자크기는 따로 수정하지 않는다. Step 1. 제목 및 소제목을 적고, ctrl + 1,2,3 을 이용하여 꾸민다.#은 기본적으로 사용하지 않는다. Step 2. 대표 이미지 설정구글 이미지 검색 혹은 https://pixabay.com/ko/ 에서 사용 권한이 적절해보이는 dropbox/이미지에 다운받고, 첨부한다. 2020. 1. 9. Python Concurrency Programming Multi-thread vs Multi-Processing vs AsyncIO https://code.luasoftware.com/tutorials/python/python3-threading-vs-multiprocessing-vs-asyncio/ Python의 default interpreter인 CPython은 GIL(Global Interpreter Lock)이 걸려 있어서 multi-thread를 구현해도, 여러 thread가 정말로 동시에 실행될 수는 없다. 그래서 대개의 경우 multi-processing을 통해서 병렬성(parallelism)를 구현한다. 그러나 multi-processing은 "almost independent"하게 job을 쪼갤 수 있는 CPU 연산이 heavy한 task.. 2020. 1. 9. Python 프로젝트 배포 및 다른 패키지 가져오기 Python 프로젝트를 export 또는 import하는 방법 1. pip install을 사용한다. 2. module관리 도구를 사용한다. 3. git clone을 한다. 1. Pip install 사용하기 먼저 pip로 install하게 하기 위해서는 setup.py와 requirements.txt를 작성해야한다. 그 다음으로 해야할 일은 python 에서 import가 가능한 프로젝트를 패키지 구조로 만드는 것이다. 즉 import 의 파이썬 코드로 사용할 수 있도록 그에 맞는 프로젝트의 구조를 만들어야한다. # 패키지 구조 만들기 출처: https://github.com/chakki-works/seqeval 위와 같이 따라서 setup.py와 requirements.txt 등 실제 실행되지 않을 .. 2020. 1. 9. 이전 1 다음