# 발음기호와 문자표현
- phoneme: 음소, 가장 작은 소리의 단위. 쉽게 말해 영어사전의 발음기호를 생각하면 된다.
- grapheme: 자소(=문자소), 가장 작은 문자의 단위. 발음기호로 표현되기 이전의 원래 문자를 의미한다. 그리고 대부분의 경우 알파벳 1개가, phoneme 1개에 대응 된다.
ex) help -> h / e / l / p
그러나 항상 phoneme과 1:1대응은 아니다. 예를 들어 shop 에서 sh는 2개의 알파벳이 묶어서 ʃ 으로 발음되므로, 2개의 알파벳이 1개의 grapheme에 대응 된다.
ex) shop -> ʃ / ɑː / p
경우에 따라서 최대 4개의 알파벳이 1개의 graphpeme에 대응 되기도 한다.
ex) weight -> w / ei / t
- monophone(=single phone): phoneme을 표기하는 방법 중에 하나. 가장 간단하고 직관적인 방법으로 발음기호를 1개씩 겹치지 않게 나열한다. ex) help -> h / e / l / p
- triphone: phoneme을 표기하는 방법 중에 하나. [좌-현재+우]의 형식으로 좌우에 등장하는 phoneme을 중복해서 같이 표기하는 방식. ex) h+e / h-e+l / e-l+p / l-p
http://www.voxforge.org/home/docs/faq/faq/what-is-the-different-between-a-monophone-and-a-triphone
# 기본 개념
* 소리: 그냥 공기(매질)가 움직이는 것은 바람이지 소리가 아니다. 공기에 주기적인 진동(앞뒤로의 수축/팽창)이 발생해야만 소리란 정보가 된다. 즉 공기를 매질로하는 파동 에너지가 바로 소리의 정체이다. 이때 파동의 진동수가 작으면 낮은 에너지를 가진 저음이 되고, 진동수가 크면 많은 에너지를 가진 고음이 된다.
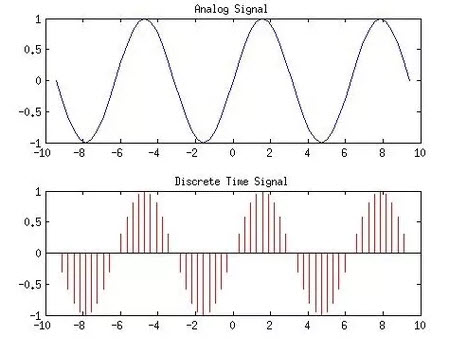
* 마이크의 녹음과정: 소리가 마이크의 떨림판에 부딪히면서 떨림판을 떨게 한다. 그 떨림판의 진동폭을 전기적으로 변환해서(발전기의 원리와 동일) +-로 기록한 소리파동에 대한 정보이다. 단, 떨림판을 진동시켜서 발생한 전기는 물리적인 analog signal이기 때문에 이를 digital signal로 변환해서 사용하는게 보편적이다. 이렇게 digital signal로 만드는 과정에 sampling이 필요하다. (스피커는 위의 과정을 정반대로 수행하는 것으로 볼 수 있다.)
* Wav 파일: 소리 파동의 높이 값(float형)을 일정한 시간 간격(sampling rate)마다 기록한 실수의 배열. 이러한 저장 방식을 PCM(Pulse-Code Modulation) 이라고 부른다.
https://www.izotope.com/en/learn/digital-audio-basics-sample-rate-and-bit-depth.html
* PCM 세부 사항
- Mono vs Stereo: Left-Right 마이크 2개에서 들어온 소리(2개의 mono)를 녹음해서 한 번에 저장한 것을 스테레오라고 한다.
- Sampling rate: data point의 x축 해상도. 즉 1초에 몇번이나 data point를 찍을지이다.
- Bit depth: data point의 y축 해상도. 각 점들의 높이(amplitude)를 구분할 수 있는 해상도. 만약 bit depth가 2 라면 오직 4단계의 y축 해상도만 존재한다.
- Bit rate: Sampling rate * Bit depth, 위 두가지 measure를 동시에 고려하는 것으로, 그 의미는 초당 bits전송량이다.

# Acoustic model
오디오 -> phoneme(혹은 grapheme 등)을 예측해주는 모델
# Phoneme Dictionary
word -> phoneme가 기록된 정보, 즉 발음기호 사전
# G2P model(Grapheme to Phoneme)
대규모 phoneme dictionary를 학습해서, 임의의 word에 대한 phoneme을 예측해주는 모델. Phoneme dictionary와의 차이점은, dictionary에 없는 word에 대한 phoneme에 대해서도 어느정도 발음을 예측할 수 있다.
# Pitch: 음의 높낮이(진동수 Hz의 크고 작음과는 다르다)
Pitch는 보다 추상적인 개념이다. 사람은 소리의 Hz가 저주파일때 더 민감하게 인지하고, 고주파로 갈수록 둔감해진다는 점에서 출발한 개념이다. 이를 just-noticeable differences(==threshold)라고 한다.
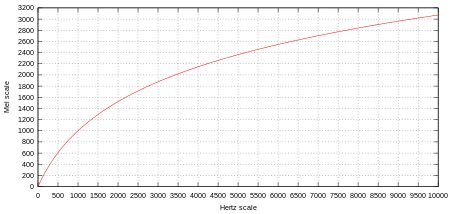
즉 사람이 인지하는 음의 높낮이는 Hz와 linear한 관계가 아니라 exponential한 관계이다. 아래 보이는 그림과 같이 옥타브의 위치가 저주파에서와 고주파에서 변동폭이 다르다는 것을 알 수 있다.

# log scale: 말 그대로, 어떤 value에 log함수를 취해서, log scale로 값을 normalize해서 표현하는 것이다.
앞에서 등장한 pitch 또한, 사람의 인지적인 관점으로 표현하려면 log scale을 취해야하는데, 이러한 표현 방식의 대표적인 것이 바로 mel-scale이다.
Spectrogram에서는 log scale이 두번 등장하는데, spectrogram 이미지에서 픽셀의 값 자체인 amplitude에 decibel 함수를 적용하는 것 또한 log scale이고, spectrogram의 y-axis인 frequency에도 또 다시 log를 취해서 mel-scale로 바꾸는 것 또한 log scale이다.
# 데시벨: 10*log_10^[에너지의 비율]을 취한것
https://ghebook.blogspot.com/2014/06/decibel-and-logarithmic-function.html
# Mel-scale: Melody scale
Mel-scale은 이러한 pitch에서 발견한 사람의 음을 인지하는 기준(threshold)을 반영한 scale 변환 함수이다. 위에서처럼 [Hz -> 음계]의 관계가 exponential하기 때문에 주파수를 바로 linear하게 다루지 말고, log함수를 통과시켜 mel scale로 바꾼다음, linear하게 다루자는 것이다.(사실 이런 scale 변환은 computer vision이나 금융AI에서도 빈번하게 일어난다.)
그래서 아래와 같은 함수를 이용해 mel-scale(log-scale)로 변환한다.
그리고 이 함수는 다음과 같이 생겼다.
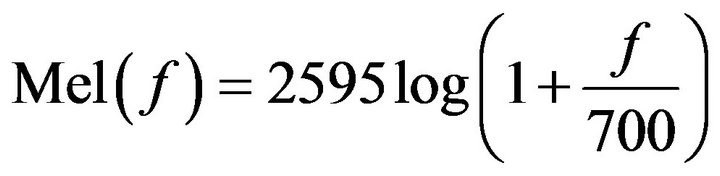
만약 mel-scale에서 다시 Hz로 변환하고 싶으면, 위 함수의 역함수(지수함수)를 이용하면 된다.
# Mel-filterbank
Mel-filterbank는 mel-scale에서 linear하게 구간을 N개로 나눠구현한 triangular filter(=triangular window)를 가리킨다. 아래 그림을 보면 직관적으로 이해할 수 있을 것이다. Mel-scale(log-scale)에서 linear하게 나누었기 때문에, 주파수 영역에서보면 지수적으로 넓어지는 것을 확인할 수 있다.
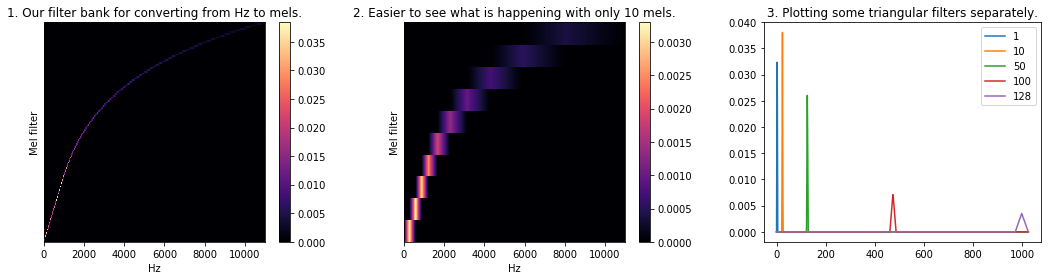
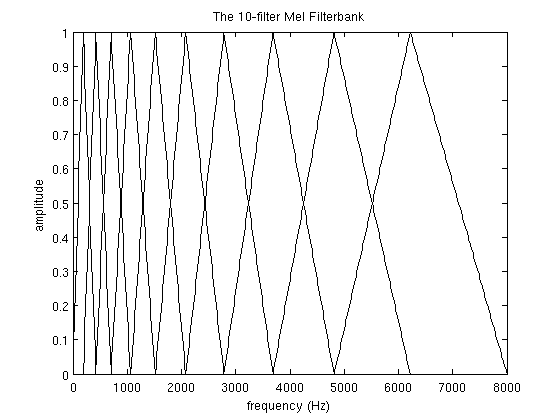
# MFCC(Mel-frequency cepstral coefficients)의 추출 과정
MFCC는 음성인식 분야에서 가장 오랫동안 표준기술로 사용된 hand-made feature이다. MFCC에 대해 이해하는 것은 음성인식 기술의 conventional 연구를 이해하는 것과 맥락을 같이한다.
- 참고문헌
* 아주 좋음: https://seungheondoh.netlify.app/blog/fft
https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
https://en.wikipedia.org/wiki/Mel-frequency_cepstrum
http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/
https://m.blog.naver.com/mylogic/220988857132
https://web.ma.utexas.edu/users/davis/reu/ch3/specgram/specgram.pdf
# 계산 과정
Mic → Wav signal
- 마이크에서 나온 전기신호가 ADC를 통과하면서 16kHz의 sampling rate로 해당 signal을 wav형태로 기록한다.
- Wav signal은 x축이 time, y축이 신호의 세기(amplitude)이다.
→ Framing → Frames
- 25ms 사이즈의 window size를 10ms step-size로 sliding하여 frame을 만든다.
- 만약 wav파일이 35ms짜리 소리라면, 2개의 윈도우가 들어갈 수 있으므로, 2개의 frame이 나온다.
→ Hamming Window → Hamming Windowed Frames
- 각 frame에 hamming window를 적용하여 spectral leakage를 줄인다.
- Spectral leakage에 대해서는 아래의 신호처리 부분을 참고한다.
→ STFT(~=DFT) → Spectrogram(=Frequency Spectrum)
- 각 frame에 short-time Fourier transform(STFT)을 적용하여 주파수 도메인으로 변환한다.
- Fourier transform에서 샘플링하는 N은 보통 256 혹은 512이다. 이 N의 값은 보통 frame의 길이, 즉 window size와 같다. 이 N값이 작으면 spectrogram에서 구분할 수 있는 frequency의 resolution도 작아지게 된다.
- FFT에서 sampling 개수의 의미: center of coordinated mass를 estimation할 때 사용되는 샘플 포인트의 개수, https://youtu.be/spUNpyF58BY?t=906
- 기본적으로 FFT를 하게 되면 time domain(x축: time, y축: amplitude)에서 frequency domain(x축: frequency, y축: magnitude)로 바뀌게 되는데, 시간을 함께 고려하기 위해 여기서 시간 차원(frame)을 추가하여, spectrogram(x축: frame, y축: frequency, color값: magnitude)이란 3차원의 heat map 데이터를 보통 사용하게 된다.
- Y-axis에는 log scale을 취할 수도 있고 그냥 놔둘 수도 있다.(선택 가능한 옵션)
- 픽셀의 값에 log scale을 취한다. (데시벨)
- Spectrogram의 y축은 Nyquist limit에 따라 원본 sampling rate의 1/2이다.
→ Power normalized → Power Spectrum(=Periodogram, Power Spectral Density)
- Frequency Spectrum에 제곱을 취하고, 다시 N으로 나누어 Power Spectrum을 만든다.
→ Mel-scale filterbanks →Mel Spectrogram
- Mel-scale이란 사람의 non-linear한 ear perception of sound를 고려한 hz의 변형된 scale이다.
- Mel-scale Filterbanks: non-linear한 구간을 가진 40개의 triangular filterbanks를 만든다.
- Mel spectrogram의 y축은 filterbank의 개수와 동일한 dim을 갖는다. 즉 40개의 각 filterbank들이 커버하는 영역의 Hz를 triangle filter로 검출하여 요약한 정보이다.
→ Take log → Log Mel Spectrogram
- log 취하는 것이 deeplearning에서는 큰 의미를 갖는다.
→ IDFT(or DCT) → MFCC
- Inverse Discrete Fourier Transfor(or Discrete Consine Transform)을 수행하고 이 계수들 중 가장 저차원의 12개만 남긴다.(주파수 도메인에서 다시 시간 도메인으로 변환하면서, feature selection이 일어남.)
- 이때 Deltas and Delta-Deltas feature를 구해서 append 하기도 한다.
- 딥러닝에서는 MFCC대신 이 과정을 생략한, Log Mel Spectrogram을 사용하기도 한다. DCT가 linear operation이기도 하고, 딥러닝에서는 12개로 축소하기 전 단계의 정보도 잘 사용될 여지가 있기 때문이다.
음성인식을 위한 신호처리
# Heisenberg's Uncertainty principle of Fourier Transform
You can either have high resolution in time or high resolution in frequency but not both at the same time. The window lengths allow you to trade off between the two.
양자역학에서 자주 등장하는 하이젠베르크의 불확정성의 원리가 신호처리에서도 동일하게 적용된다. Time resolution과 Frequency resolution에는 trade off가 존재해서 둘중 하나를 정확하게 알려면, 다른 하나를 포기해야한다. 예를 들어 window size를 키우고 그 size 만큼의 point로 FFT를 하면 더 높은 resolution을 가진 frequency를 구할 수 있다. 즉 1 Hz와 2Hz를 구분할 수 있게 되는 것이다. 그러나 이렇게 하게 되면 그 길어진 window 중에서 정확히 어느 시점에서 그 frequency event가 발생했는지는 더 불명확해 진다. 반대로 정확히 언제인지를 알아내고자 window를 줄이면, 더 낮은 resolution의 frequency를 얻게 된다.
https://en.wikipedia.org/wiki/Fourier_transform#Uncertainty_principle
https://en.wikipedia.org/wiki/Uncertainty_principle#Signal_processing
https://dsp.stackexchange.com/questions/248/how-do-i-optimize-the-window-lengths-in-stft
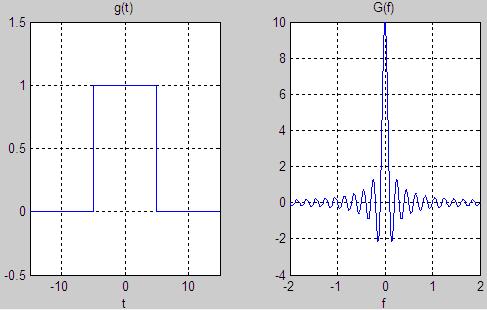
# Spectral Leakage
기본적으로 Fourier transform은 길이가 무한한 wav에 대한 infinite Fourier transform 알고리즘이다. 그런데 우리는 실제로는 길이가 유한한 wav를, 다시 짧은 window 단위로 자른 frame에 대해서 Fourier transform을 적용한다. 그런데 문제는이 wav를 사각형 window로 잘라서 frame으로 만드는 과정이 엄밀히 말해 rectangule filter를 wav에 적용하는 것과 완벽히 동치이다. 그래서 이렇게 만든 frame에 Fourier transform을 하게 되면 sinc function에 해당하는 noise가 발생하는데 그 이유는 rectangule filter를 inverse Fourier transform을 하면 sinc function이 되기 때문이다.
이러한 일종의 noise를 spectral leakage라 부르는데, 이를 해결하기 위해서 hamming window를 frame에 적용하거나, frame의 양 끝에 zero-padding을 넣는 등의 휴리스틱 솔루션들이 많이 만들어지게 되었다.
https://stackoverflow.com/a/21641171/7573626
https://dspillustrations.com/pages/posts/misc/spectral-leakage-zero-padding-and-frequency-resolution.html
# Window function: Sliding window에 사용되는 다양한 모양을 가진 filter function
다양한 window function이 사용되는 이유는 바로 spectral leakage를 완화시키기 위함이다.spectral leakage는유한한 길이로 제한하는 과정에서 rectangle filter가 사용되기 때문에 발생한다. mel-filterbank에서는 mel-amplitude 공간에 삼각형 filter를 사용했지만, 사실 삼각형이 아니라 온갖 종류의 다양한 모양을 가진 filter를 적용할 수 있다.
https://en.wikipedia.org/wiki/Window_function#Triangular_window
* Hamming window
여러가지 Window function중 하나로, 모양새는 truncated gaussian분포처럼 생겼는데, 실제로는 cosine함수를 이용해 구현한 filter이다.
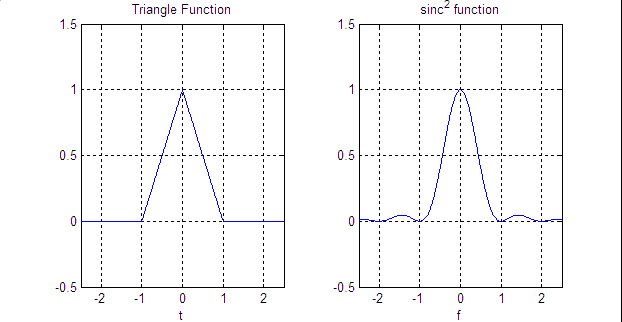
* Rectangle filter
sincNet에서 사용되는 rectangle filter는 sinc function과 동치이다.
* Triangle filter
Mel-filterbank에서 사용되는 triangle filter는 sinc^2 function과 동치이다.
# 모델 비교
- SincNet vs 1DConv: first layer의 자유도를 완전히 풀어서 복잡한 filter도 학습 할지, 아니면 딱 band-pass filter형태로만 학습할지의 차이.
- SincNet vs Fourier Trasnform: 똑같이 spectrogram을 구하더라도, 푸리에변환이 어찌되었든 적분연산을 해야하므로 computing overhead가 있음.
# SincNet과 Mel spectrogram의 차이
- SincNet은 rectangle filter(=band pass filter)의 high cut, low cut에 해당하는 f1, f2 두 파라미터를 learining한다. 이에 반해 Mel spectrogram은 해당 파라미터들이 모두 fixed되어 변하지 않는다.
- SincNet은 learnable rectangle filter -> hamming window를 사용하고, Mel spectrogram은 hamming window -> fixed triangle filter를 사용한다.
- SincNet으로 구한 (learnable) mel spectrogram은 time domain에서 band-pass filter로 부터 바로 구한 spectrogram인 반면, Mel spectrogram으로 추출된 feature들은 Fourier transform을 통해 frequency domain에서 구해진 mel spectrogram이다.
# Spectrogram을 구하는 두가지 방법
두가지 방법으로 구한 spectrogram은 서로 특정한 조건하에서 동치이다.https://en.wikipedia.org/wiki/Spectrogram#Generation
1. band-pass filter 이용
Time-domain에서 바로 K개의 band-pass filter를 각 frame마다 적용해서 매 frame에 대한 K dim feature를 뽑아서 spectrogram을 만든다.
2. Fourier transform 이용
각 frame에 대해 Fourier transform을 한다음
Implementation
Librosa 파이썬 library
mel_spec = (
librosa.feature.melspectrogram(
to_np(wave_data[i]),
sr=sample_rate,
n_fft=kernel_size,
hop_length=stride,
n_mels=out_channels,
window=window,
center=False
# win_length=512,
)
)그리고 librosa.feature extraction의 경우 무조건 1개의 wav file에 대해서만 처리가 가능해서(즉 batch가 안된다) 매우 느리다. SincNet과 비교해서 4배정도 더 느린 것으로 나타났다. 따라서 미리 모든 file에 대해 feature를 뽑아놓고 사용하는 것이 권장된다.
Char-level ASR 모델이 존재하는 word만 생성하도록 하기
1. Trie 자료구조 활용
https://en.wikipedia.org/wiki/Trie
Trie - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search K-ary search tree data structure This article is about a tree data structure. For the French commune, see Trie-sur-Baïse. TrieTypetreeInvented1960Invented byEdward Fredkin, Axel Thue,
en.wikipedia.org
일종의 Heuristic으로 만든 CRF를 적용하여, 존재하는 word의 character만 예측하도록 강제하는 것이다.
2. Char-level LM fusion
Trie 자료 구조의 기계학습 버전이라고 이해하면 된다
'Research > Machine Learning' 카테고리의 다른 글
| Advanced Supervised Learning (0) | 2020.01.28 |
|---|---|
| The Bitter Lesson 번역 (0) | 2020.01.17 |
| 소리 합성 (0) | 2019.12.09 |
| 물리학에 기반한 모델 (0) | 2019.05.15 |
| 강화학습, Exponentially weighted average계산하기 (0) | 2019.01.22 |


댓글